
 1. GAN简介
1. GAN简介
"干饭人,干饭魂,干饭都是人上人"。
此GAN饭人非彼干饭人。本文要讲的GAN是Goodfellow2014提出的生成产生对抗模型,即Generative Adversarial Nets。那么GAN到底有什么神奇的地方?
常规的深度学习任务如图像分类,目标检测以及语义分割或者实例分割,这些任务的结果都可以归结为预测。图像分类是预测单一的类别,目标检测是预测bbox和类别,语义分割或者实例分割是预测每个像素的类别。而GAN是生成一个新的东西如一个图片。
GAN的原理用一句话来说明:
通过对抗的方式,去学习数据分布的生成式模型。GAN是无监督的过程,能够捕捉数据集的分布,以便于可以从随机噪声中生成同样分布的数据
GAN的组成:判别式模型和生成式模型的左右手博弈
D判别式模型:学习真假边界,判断数据是真的还是假的 G生成式模型:学习数据分布并生成数据
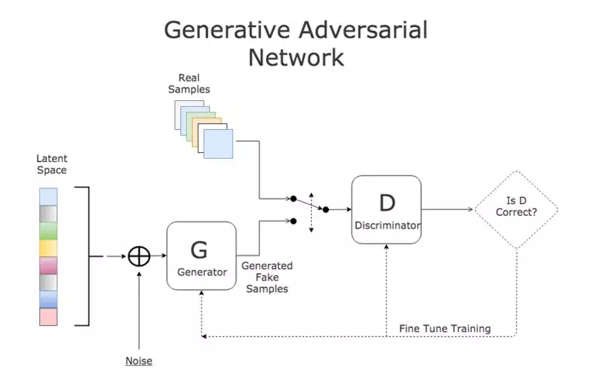
GAN经典的loss如下(minmax体现的就是对抗)
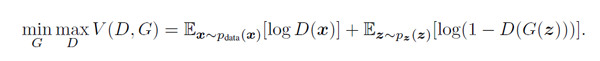
2. 实战cycleGAN 风格转换
了解了GAN的作用,来体验的GAN的神奇效果。这里以cycleGAN为例子来实现图像的风格转换。所谓的风格转换就是改变原始图片的风格,如下图左边是原图,中间是风格图(梵高画),生成后是右边的具有梵高风格的原图,可以看到总体上生成后的图保留大部分原图的内容。

2.1 cycleGAN简介
cycleGAN本质上和GAN是一样的,是学习数据集中潜在的数据分布。GAN是从随机噪声生成同分布的图片,cycleGAN是在有意义的图上加上学习到的分布从而生成另一个领域的图。cycleGAN假设image-to-image的两个领域存在的潜在的联系。
众所周知,GAN的映射函数很难保证生成图片的有效性。cycleGAN利用cycle consistency来保证生成的图片与输入图片的结构上一致性。我们看下cycleGAN的结构:
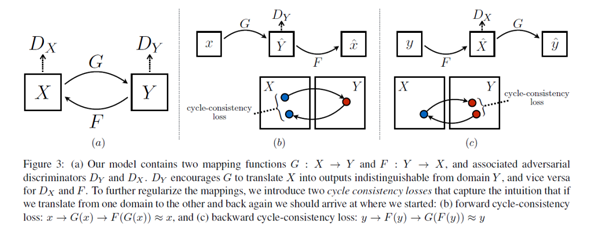
特点总结如下:
两路GAN:两个生成器[ G:X->Y , F:Y->X ] 和两个判别器[Dx, Dy], G和Dy目的是生成的对象,Dy(正类是Y领域)无法判别。同理F和Dx也是一样的。 cycle consistency:G是生成Y的生成器, F是生成X的生成器,cycle consistency是为了约束G和F生成的对象的范围, 是的G生成的对象通过F生成器能够回到原始的领域如:x->G(x)->F(G(x))=x
对抗loss如下:
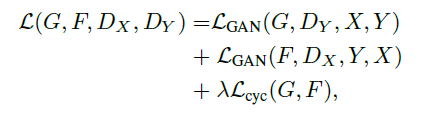
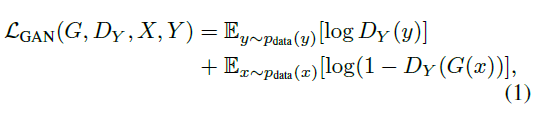
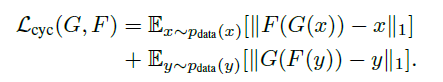
2.2 实现cycleGAN
2.2.1 生成器
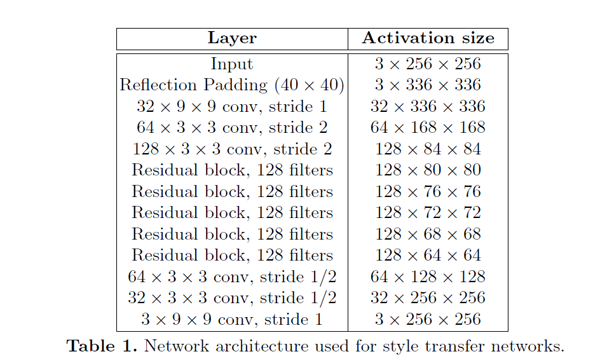
从上面简介中生成器有两个生成器,一个是正向,一个是反向的。结构是参考论文Perceptual Losses for Real-Time Style Transfer and Super-Resolution: Supplementary Material。大致可以分为:下采样 + residual 残差block + 上采样,如下图(摘自论文):
实现上下采样是stride=2的卷积, 上采样用nn.Upsample:
# 残差block class ResidualBlock(nn.Module): def __init__(self, in_features): super(ResidualBlock, self).__init__() self.block = nn.Sequential( nn.ReflectionPad2d(1), nn.Conv2d(in_features, in_features, 3), nn.InstanceNorm2d(in_features), nn.ReLU(inplace=True), nn.ReflectionPad2d(1), nn.Conv2d(in_features, in_features, 3), nn.InstanceNorm2d(in_features), ) def forward(self, x): return x + self.block(x) class GeneratorResNet(nn.Module): def __init__(self, input_shape, num_residual_blocks): super(GeneratorResNet, self).__init__() channels = input_shape[0] # Initial convolution block out_features = 64 model = [ nn.ReflectionPad2d(channels), nn.Conv2d(channels, out_features, 7), nn.InstanceNorm2d(out_features), nn.ReLU(inplace=True), ] in_features = out_features # Downsampling for _ in range(2): out_features *= 2 model += [ nn.Conv2d(in_features, out_features, 3, stride=2, padding=1), nn.InstanceNorm2d(out_features), nn.ReLU(inplace=True), ] in_features = out_features # Residual blocks for _ in range(num_residual_blocks): model += [ResidualBlock(out_features)] # Upsampling for _ in range(2): out_features //= 2 model += [ nn.Upsample(scale_factor=2), nn.Conv2d(in_features, out_features, 3, stride=1, padding=1), nn.InstanceNorm2d(out_features), nn.ReLU(inplace=True), ] in_features = out_features # Output layer model += [nn.ReflectionPad2d(channels), nn.Conv2d(out_features, channels, 7), nn.Tanh()] self.model = nn.Sequential(*model) def forward(self, x): return self.model(x)
2.2.2 判别器
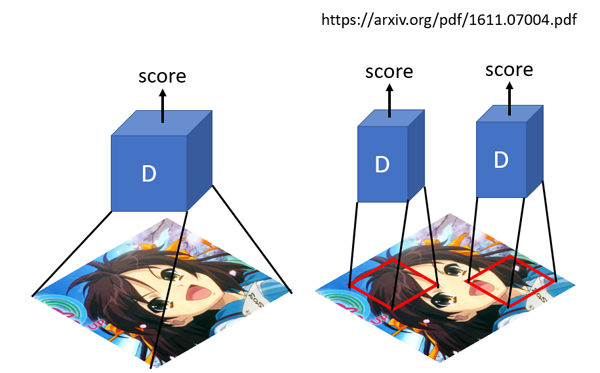
传统的GAN 判别器输出的是一个值,判断真假的程度。而patchGAN输出是N*N值,每一个值代表着原始图像上的一定大小的感受野,直观上就是对原图上crop下可重复的一部分区域进行判断真假,可以认为是一个全卷积网络,最早是在pix2pix提出(Image-to-Image Translation with Conditional Adversarial Networks)。好处是参数少,另外一个从局部可以更好的抓取高频信息。
class Discriminator(nn.Module): def __init__(self, input_shape): super(Discriminator, self).__init__() channels, height, width = input_shape # Calculate output shape of image discriminator (PatchGAN) self.output_shape = (1, height // 2 ** 4, width // 2 ** 4) def discriminator_block(in_filters, out_filters, normalize=True): """Returns downsampling layers of each discriminator block""" layers = [nn.Conv2d(in_filters, out_filters, 4, stride=2, padding=1)] if normalize: layers.append(nn.InstanceNorm2d(out_filters)) layers.append(nn.LeakyReLU(0.2, inplace=True)) return layers self.model = nn.Sequential( *discriminator_block(channels, 64, normalize=False), *discriminator_block(64, 128), *discriminator_block(128, 256), *discriminator_block(256, 512), nn.ZeroPad2d((1, 0, 1, 0)), nn.Conv2d(512, 1, 4, padding=1) ) def forward(self, img): return self.model(img)
(免责声明:本网站内容主要来自原创、合作媒体供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )
相关阅读
- 2026 世界机器人大赛华南锦标赛(三亚)圆满收官
- 11大购车权益10.99万元起 长续航智美纯电轿跑风云A9满电上市
- 2026 世界机器人大赛华南锦标赛(三亚)圆满收官
- TATA木门明确行业首个静音标准,“静有级·竞无限”引领好房子新赛道
- 承接奇瑞2000万交付里程碑,风云A9将于7月25日全球上市
- 静候登场!TATA木门2026(第二届)美好人居论坛暨静音新品发布会即将启幕
- 海风揽科创 少年竞锋芒2026世界机器人大赛华南锦标赛(三亚)盛大启幕
- 早鸟优惠进行中 | CCF HPC China 2026 注册已开启
- 魔法原子WAIC2026亮相Magic-VLA K02新任务 打造物理AI平台大脑
- 三星发布新款 990 固态硬盘,具备强悍读写性能与优化功耗表现